本篇文章给各位网友带来的资讯是:一个 AI 玩 41 个游戏,谷歌最新多游戏决策 Transformer 综合表现分是 DQN 的两倍 详情请欣赏下文
谷歌 AI 宣布,在多任务学习上取得了巨大进展:他们搞出一个会玩 41 款雅达利游戏的 AI,而且采用的新训练方法比起其他算法,训练效率大大提升!

此前会玩星际争霸的 CherryPi 和火出圈的 AlphaGo 都属于单游戏智能体(Agent),也就是说,一个 AI 只会玩一种游戏。多游戏智能体这边,现有的训练算法屈指可数:主要包括时间差分学习算法(Temporal Difference Learning,TD)和行为克隆(Behavioral Cloning,BC)等。
不过为了让一个智能体同时学会玩多款游戏,之前的这些方法的训练过程都很漫长。
现在,谷歌采用了一个新决策 Transformer 架构来训练智能体,能够在少量的新游戏数据上迅速进行微调,使训练速度变得更快,而且训练效果也是杠杠的 —— 该多游戏智能体玩 41 款游戏的表现综合得分,是 DQN 等其他多游戏智能体的 2 倍左右,甚至可以和只在单个游戏上训练的智能体媲美。
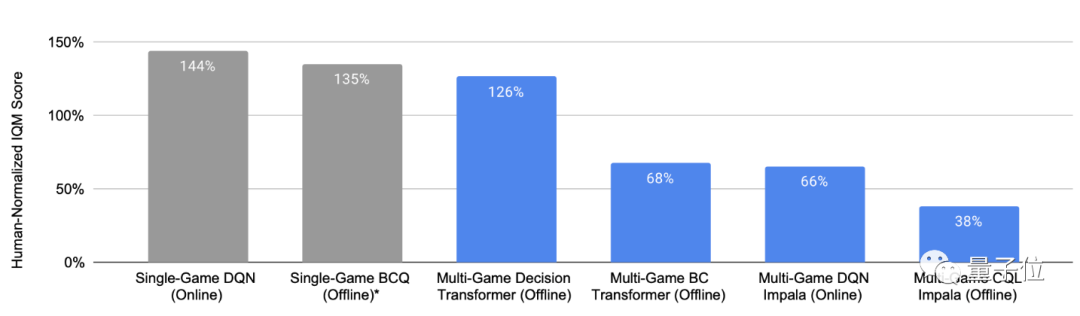
△ 100% 表示每款游戏的人类平均水平,灰色条代表单游戏智能体,蓝色条代表多游戏智能体
下面就来看看这个性能优秀的多游戏智能体。
新决策 Transformer 三大亮点
这个处理多款游戏学习的 Transformer,采用了一个将强化学习(Reinforcement Learning,RL)问题视为条件序列建模的架构,它根据智能体和环境之间过去的互动以及预期收益,来指导智能体的下一步活动。
说到强化学习,其讨论的主要问题是:在训练过程中,一个面对复杂环境的智能体,如何通过在每个 Time Step 里感知当前状态和 Reward 来指导下一步动作,以最终最大化累计收益(Return)。
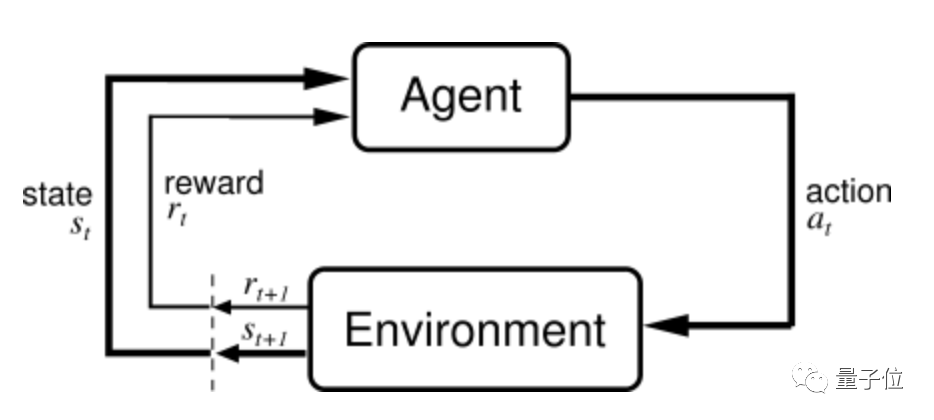
传统的深度 RL 智能体(如 DQN、SimPLe、Dreamer 等)会学习一个策略梯度(Policy Gradient),让高 Reward 的轨迹出现概率变大,低 Reward 的轨迹出现概率变小。
这就导致它出现一些问题:即需要手动定义一个信息量很大的标量值范围,包含针对于每个特定游戏的适当信息。这是个相当浩大的工程,而且拓展性较差。
为了解决这个问题,谷歌团队提出了一个新方法。
训练纳入数据更多样化
谷歌的这个新决策 Transformer,把从入门玩家到高级玩家的经验数据都映射到相应的收益量级(Return Magnitude)中。开发者们认为,这样可以让 AI 模型更全面地“了解”游戏,从而让其更稳定并提高其玩游戏的水平。
他们根据智能体在训练期间与环境的互动,建立了一个收益的大小分布模型。在这个智能体玩游戏时,只需添加一个优化偏差来提升高 Reward 出现的概率。
此外,为了在训练期间更全面地捕捉智能体与环境互动的时空模式,开发者还将输入的全局图像改成了像素块,这样模型就可以关注局部动态,以掌握游戏相关的更多细节信息。
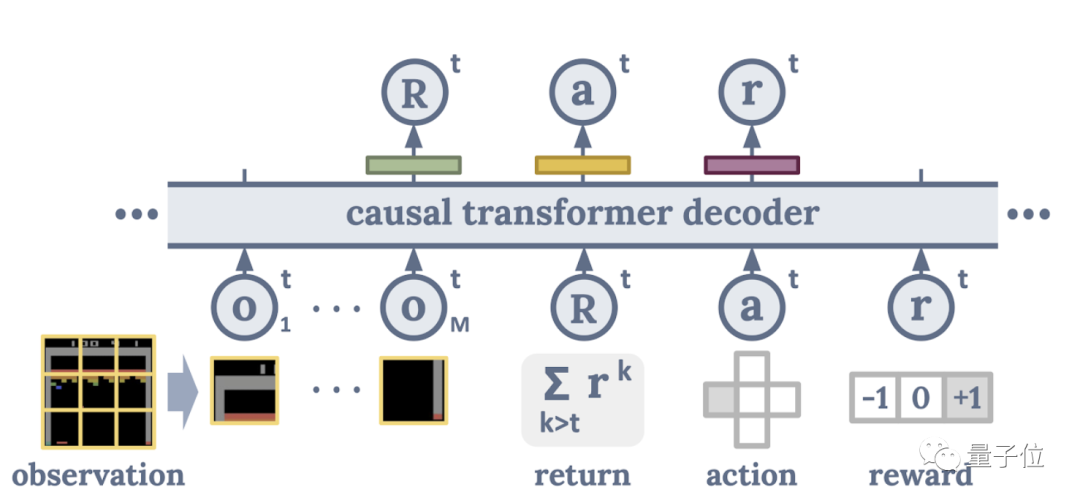
△ 决策 Transformer 基本架构示意图
可视化智能体训练过程
此外,开发者们还别出心裁地将智能体的行为可视化。然后他们发现,这个多游戏决策智能体一直都在关注着包含关键环境特征等重要信息的区域,而且它还可以“一心多用”:即同时关注多个重点。

△ 红色越亮表示智能体对那块像素的关注度越高
这种多样化注意力分配也提高了模型的性能。
拓展性更好
如今规模已成为许多机器学习相关突破的重要驱动力之一,而规模拓展一般是通过增加 Transformer 模型中的参数数量来实现的。研究者发现,这个多游戏决策 Transformer 也是类似的:随着规模扩大,和其他模型相比,其性能提升显著。
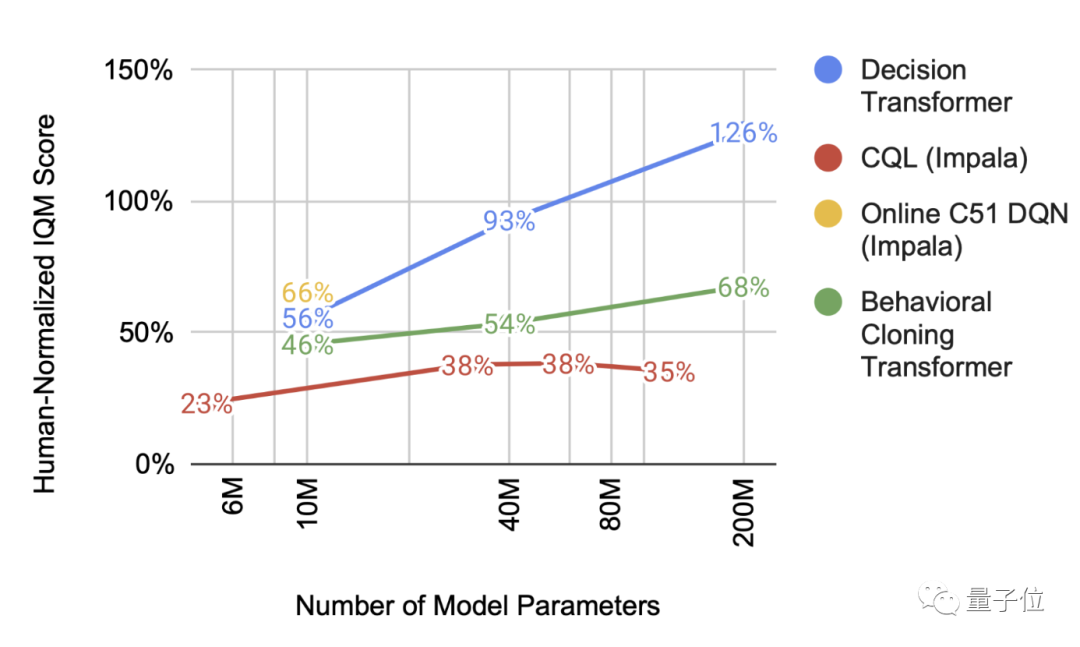
Facebook 也在研究决策 Transformer
谷歌 AI 使用决策 Transformer 不仅提高了 AI 玩多个游戏的水平,还提升了多游戏智能体的扩展性。
除此之外,据谷歌大脑、加州大学伯克利分校和 Facebook AI Research 合作的一篇论文介绍,决策 Transformer 架构在强化学习研究平台 OpenAI Gym 和 Key-to-Door 任务上也表现出色。

或许决策 Transformer 正是通用人工智能(AGI)发展的关键因素之一。
对了,谷歌 AI 表示,相关代码和 Checkpoint 会在 GitHub 上陆续开源,感兴趣的小伙伴们可以去看看~
传送门:
https://github.com/google-research/google-research/tree/master/multi_game_dt
参考链接:
[1]https://twitter.com/GoogleAI/status/1550260410686644224
[2]https://ai.googleblog.com/2022/07/training-generalist-agents-with-multi.html
[3]https://arxiv.org/abs/2106.01345
[4]https://zhuanlan.zhihu.com/p/354618420
© 版权声明
文章版权归作者所有,未经允许请勿转载。

版权声明:
1、IT大王遵守相关法律法规,由于本站资源全部来源于网络程序/投稿,故资源量太大无法一一准确核实资源侵权的真实性;
2、出于传递信息之目的,故IT大王可能会误刊发损害或影响您的合法权益,请您积极与我们联系处理(所有内容不代表本站观点与立场);
3、因时间、精力有限,我们无法一一核实每一条消息的真实性,但我们会在发布之前尽最大努力来核实这些信息;
4、无论出于何种目的要求本站删除内容,您均需要提供根据国家版权局发布的示范格式
《要求删除或断开链接侵权网络内容的通知》:https://itdw.cn/ziliao/sfgs.pdf,
国家知识产权局《要求删除或断开链接侵权网络内容的通知》填写说明: http://www.ncac.gov.cn/chinacopyright/contents/12227/342400.shtml
未按照国家知识产权局格式通知一律不予处理;请按照此通知格式填写发至本站的邮箱 wl6@163.com
1、IT大王遵守相关法律法规,由于本站资源全部来源于网络程序/投稿,故资源量太大无法一一准确核实资源侵权的真实性;
2、出于传递信息之目的,故IT大王可能会误刊发损害或影响您的合法权益,请您积极与我们联系处理(所有内容不代表本站观点与立场);
3、因时间、精力有限,我们无法一一核实每一条消息的真实性,但我们会在发布之前尽最大努力来核实这些信息;
4、无论出于何种目的要求本站删除内容,您均需要提供根据国家版权局发布的示范格式
《要求删除或断开链接侵权网络内容的通知》:https://itdw.cn/ziliao/sfgs.pdf,
国家知识产权局《要求删除或断开链接侵权网络内容的通知》填写说明: http://www.ncac.gov.cn/chinacopyright/contents/12227/342400.shtml
未按照国家知识产权局格式通知一律不予处理;请按照此通知格式填写发至本站的邮箱 wl6@163.com